前回は、AI生成Markdownを壊さないための書き方について整理しました。
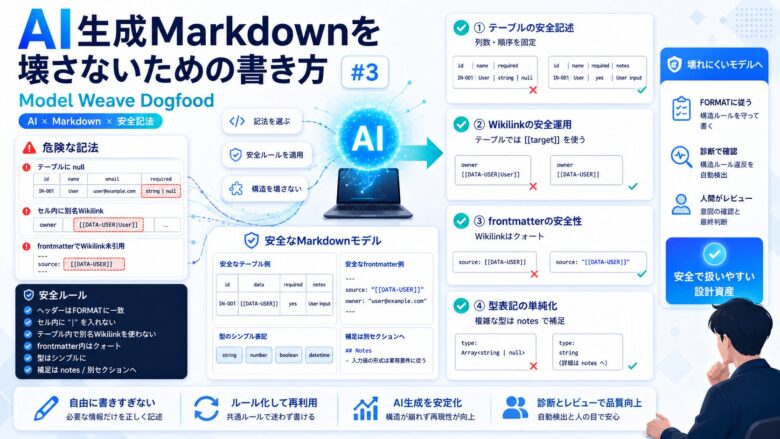
Markdownテーブルでは | を避ける。
frontmatter内のWikilinkはクォートする。
型表記は単純にする。
定義外の情報は notes や別セクションに逃がす。
こうしたルールは、AIにMarkdownモデルを生成・更新させるうえでかなり重要でした。
ただ、Dogfoodを進める中で、もう一つ大きな課題が見えてきました。
それは、AIに何を情報源として渡すかです。
AIに良い出力をしてもらうには、良いプロンプトを書くことが重要です。
しかし、それだけでは足りません。
AIが参照している情報が古い。
必要なソースが含まれていない。
将来構想と実装済み機能が混ざっている。
FORMAT仕様が曖昧になっている。
こうした状態では、どれだけプロンプトを工夫しても、出力はずれていきます。
今回は、Model WeaveのDogfoodを通じて分かった「AIに渡す情報源の整え方」について書きます。
AIは手元にある情報から推論する
AIを使っていると、つい「AIが分かってくれるはず」と思ってしまいます。
しかし、実際にはAIは、与えられた情報を元に推論しています。
その情報が不足していれば、不足したまま補完します。
古い情報が混ざっていれば、古い前提を使います。
構想段階の情報が実装済みのように書かれていれば、それを実装済みとして扱うことがあります。
Dogfoodでは、この問題が何度か起きました。
たとえば、Model Weave自身をモデル化するために、ソースコード、README、FORMAT仕様、DogfoodモデルをAIに読ませていました。
このとき、AIが参照している情報源に偏りがあると、次のようなズレが出ます。
- 実装済みではない機能を、実装済みとして扱う
- 古いFORMATを前提にMarkdownを生成する
- Dogfoodモデル上の将来構想を、本体コードに存在する機能として扱う
- ソースに存在しないファイルや関数を前提に修正案を出す
- パーサーの制約を無視して、見た目だけ自然なMarkdownを作る
これはAIの能力不足というより、情報源の管理不足に近い問題です。
AIは、与えられた材料で料理します。
材料が古かったり、足りなかったり、ラベルが間違っていたりすれば、出てくるものもずれます。
ソースだけでは足りない
まず、AIに既存システムの設計を可視化させるなら、ソースコードは重要です。
実装の事実は、基本的にはソースにあります。
どの機能がどのファイルにあるか。
どのパーサーがどのFORMATを読んでいるか。
どのレンダラーがどのモデルを表示しているか。
こうした情報は、ソースを読まないと分かりません。
しかし、ソースだけを渡せば十分かというと、そうでもありません。
ソースコードには、実装の詳細はあります。
でも、設計上の意図や、ドキュメント上の整理、今後の構想までは必ずしも分かりません。
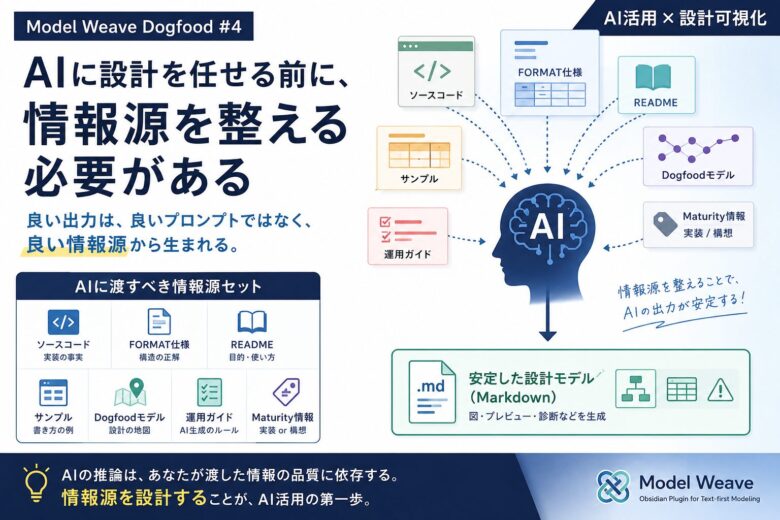
たとえば、Model Weaveでは、MarkdownのFORMAT仕様やサンプル、README、Dogfoodモデルがそれぞれ別の役割を持っています。
- ソースコード:現在の実装
- FORMAT仕様:Markdownモデルとして守るべき構造
- README:ツールの目的や利用者向け説明
- サンプル:実際の記述例
- Dogfoodモデル:Model Weave自身を理解するための設計地図
- 運用ガイド:AI生成時に守るべきルール
AIに設計モデルを作らせるなら、これらを組み合わせて渡す必要があります。
ソースだけでは、構造の意図が不足します。
ドキュメントだけでは、実装の事実が不足します。
Dogfoodモデルだけでは、それが実装済みなのか構想なのかが曖昧になることがあります。
つまり、必要なのは単一の正解ファイルではなく、役割が分かれた情報源セットです。
Dogfoodモデルは便利だが、誤解も生む
Dogfoodモデルはかなり便利でした。
Model Weave自身の構造を、Model WeaveのMarkdownモデルとして整理しておくことで、機能・FORMAT・ソース・ドキュメントの関係を見やすくできます。
人間にとっても読みやすい。
AIにとっても、構造化された文脈として扱いやすい。
しかし、ここで問題も出ました。
Dogfoodモデルには、現在の実装だけでなく、将来構想も含まれることがあります。
たとえば、
- 今後作りたいExplorer
- まだ実験段階のFORMAT
- 将来的なSource Links活用
- Reference Explorerのような構想
- 実装前の画面や運用アイデア
こうした情報をモデル内に書くこと自体は有用です。
設計メモとして残しておく価値があります。
しかし、AIにそのまま読ませると危険です。
AIは、Dogfoodモデル上に書かれている機能を、実装済みの機能として扱うことがあります。
「このモデルに書かれている」
だから、
「本体にも実装されているはず」
と推論してしまう。
その結果、未実装機能を前提にした修正指示や、存在しないファイルへの変更案が出ることがあります。
この経験から、Dogfoodモデルには maturity や status のような区分が必要だと分かりました。
実装済みと将来構想を分ける
AIに渡す情報源では、次の区別がとても重要です。
- 実装済み
- 実験中
- 仕様検討中
- 将来構想
- メモ
- TODO
人間は文脈で判断できます。
「ああ、これは将来やりたいことだな」
「これはまだ案の段階だな」
「これは今の実装を説明しているな」
と読み分けられます。
しかし、AIに対しては明示しないと危険です。
Dogfoodモデルでは、将来構想を含める場合、それが実装済みではないことを分かるようにする必要がありました。
たとえば、次のような記述です。
## Maturity
- status: future
- implementation: not implemented
- notes: This is a design idea, not an implemented feature.あるいは、READMEやモデルの索引で、フォルダ単位に状態を分ける方法もあります。
implemented/
experimental/
future/
notes/重要なのは、AIが読んだときに、
これは今ある機能なのか
それとも将来構想なのか
を判断できるようにしておくことです。
これをしないと、AIは構想を事実として扱います。
.gitignore 対象のファイル問題
今回のDogfoodでは、もう一つ実務的な問題がありました。
AIツールによっては、プロジェクト内のすべてのファイルを同じように読めるわけではありません。
たとえば、Geminiを使っていた際、途中から .gitignore の対象になっているソースをうまく読めない場面がありました。
これにより、AIが参照できる情報源が、こちらの想定とずれていました。
人間側は、
このファイルも読めているはず
と思っている。
でもAI側は、
そのファイルを見ていない
という状態です。
このズレはかなり危険です。
AIは、読めていないことを常に明確に警告してくれるとは限りません。
読めている範囲の情報から、それらしい答えを出します。
その結果、
- 実装の前提が古い
- 参照すべきファイルが抜ける
- 存在しない構造を前提にする
- 重要な制約を見落とす
といったことが起こります。
この経験から、AIに作業を依頼する前に、
を確認する必要があると感じました。
情報源を明示的に揃える
そこで、Dogfood作業では、AIに渡す情報源を明示的に揃える方向にしました。
具体的には、次のようなものです。
- 最新のソースコード
- 最新のDogfoodモデル
- README
- FORMAT仕様
- サンプル
- AI生成運用ガイド
- Markdownテーブル安全記述ガイド
- frontmatter Wikilink安全記述ガイド
- 実装状態を示すREADMEや索引
このように、AIに読ませる情報源をセットとして整えます。
ここで大事なのは、単にファイルをたくさん渡すことではありません。
それぞれの役割を分けることです。
このように役割を整理しておくと、AIへの指示も安定します。
たとえば、
といった指示が出しやすくなります。
最新情報をどれにするか
情報源を複数渡すと、今度は別の問題が出ます。
それは、
どの情報を優先するか
です。
ソースとドキュメントが食い違っている。
Dogfoodモデルと実装が食い違っている。
FORMAT仕様とサンプルが食い違っている。
こうしたことは普通に起こります。
この場合、AIには優先順位を決めておく必要があります。
たとえば、Model WeaveのDogfoodでは、次のような優先順位が考えられます。
- 実装確認はソースコードを優先する
- Markdown構造はFORMAT仕様を優先する
- 利用者向け説明はREADMEを参照する
- 記述例はsamplesを参考にする
- Dogfoodモデルは構造理解の補助として使う
- 将来構想は実装済みと区別する
この優先順位がないと、AIはその場で都合よく情報を混ぜます。
そして、人間から見るともっともらしいが、実際には根拠が曖昧な出力になります。
AIに設計を任せるときは、
何を読むか
だけでなく、
矛盾したときに何を優先するか
まで決める必要があります。
AIへの指示は短くなる
情報源を整えると、AIへの指示はむしろ短くできます。
毎回長いプロンプトで、
- テーブルヘッダーを守って
- Wikilinkをクォートして
- 未実装機能を実装済みにしないで
- FORMATを確認して
- Source Linksはこう扱って
- notesに逃がして
と書くのは大変です。
しかも抜けます。
しかし、これらをガイドやREADMEにまとめておけば、AIには次のように言えます。
もちろん万能ではありません。
それでも、毎回プロンプトに全部詰め込むよりは安定します。
プロンプトで頑張るのではなく、AIが参照する作業環境を整える。
これは今回の大きな学びでした。
人間のレビューはなくならない
情報源を整えれば、AIの出力は安定します。
しかし、それでも人間のレビューは必要です。
特に、設計モデルでは次のような判断が残ります。
- この抽象化の粒度でよいか
- この関係をモデルに出すべきか
- この機能は実装詳細か、設計要素か
- notesに書くべきか、別モデルに分けるべきか
- futureとして残す価値があるか
- ソースとの対応は妥当か
AIは初稿を作るのが得意です。
大量の情報を整理し、たたき台を作るのはかなり強いです。
しかし、何を設計資産として残すかは、人間の判断が必要です。
今回のDogfoodでも、AIが作ったモデルをそのまま採用するのではなく、人間が確認し、修正し、必要に応じてルールを追加しました。
AIに任せる範囲と、人間が判断する範囲を分ける。
これも、AI設計可視化では重要です。
おわりに
AIで設計を可視化するには、プロンプトだけでは足りません。
ソースコード、FORMAT仕様、README、サンプル、Dogfoodモデル、運用ガイド。
これらを情報源として整え、役割と優先順位を決める必要があります。
特に重要なのは、実装済みと将来構想を分けることです。
AIは、書かれているものを自然に混ぜます。
だから、人間が「これは事実」「これは構想」「これはルール」「これは例」と分かるように整理しておく必要があります。
今回のDogfoodで分かったのは、AIに設計を任せる前に、AIが読む情報源を設計する必要があるということです。
設計を可視化するには、まず情報源を可視化する。
どのファイルが実装の事実なのか。
どのファイルがFORMATの正解なのか。
どのファイルがAI生成時のルールなのか。
どのモデルがfutureなのか。
ここを整えることで、AIの出力はかなり安定します。
次回は、設計モデルから元コードへ戻るための導線、つまりSource Linksとコードジャンプについて書いていきます。
Model Weave Dogfoodサンプルはこちらから
今回紹介している初回公開版ソースベースDogfood を公開しています。
ご興味のある方は是非ご覧ください。
コメント