
前回は、Model Weave自身をModel Weaveでモデル化するDogfoodの取り組みについて書きました。
Model Weaveは、Markdownを正本として、設計モデルや図、プレビュー、診断結果などを扱うためのObsidianプラグインです。
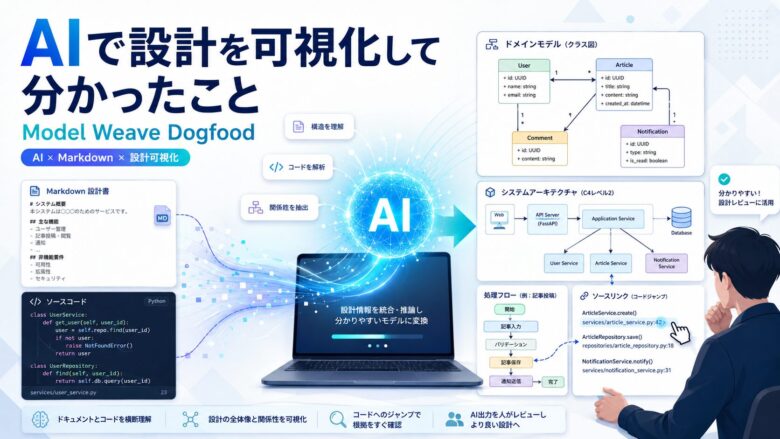
今回のDogfoodでは、Model WeaveのソースコードやドキュメントをAIに読ませ、Model Weave形式のMarkdownモデルを生成・更新していきました。
この試み自体はかなり有効でした。
人間がゼロから構造を整理するより、AIに初稿を作らせた方が速い。
ソースやREADME、仕様メモを元に、機能の一覧や関係性をそれらしく整理することもできます。
ただし、実際にやってみると、すぐに問題も見えてきました。
AIが生成したMarkdownは、人間が読むだけなら自然に見えます。
しかし、それをModel Weaveのモデルとしてパースし、図やプレビューに変換しようとすると、構造が壊れていることがあります。
今回は、その中でも特に大きかった Markdownテーブルの崩れ と FORMAT不一致 の話を整理します。
人間には自然でも、パーサーには壊れている
AIは、文脈を見て「こういう列があった方が便利そうだ」と判断することがあります。
たとえば、あるモデルのInputsセクションに、次のようなテーブルが必要だったとします。
| id | data | source | required | notes |
|---|---|---|---|---|ところがAIは、他のモデルで ref 列を見ていたり、「参照先を書いた方が便利そう」と判断したりして、次のようなテーブルを作ることがあります。
| id | data | source | required | ref | notes |
|---|---|---|---|---|---|人間が読む分には、それほど不自然ではありません。
むしろ「refがあった方が便利そう」に見えます。
しかし、Model Weaveのパーサーは、モデル種別ごとのFORMATに従ってテーブルを読み取ります。
期待している列構成と実際の列構成が違えば、正しく解析できません。
AIにとっては親切な補完でも、構造化データとしては破損になります。
AIは“似ている形式”を混ぜる
特に厄介だったのは、AIが似た形式を混ぜることです。
たとえば、data_object、app_process、rule などは、どれもMarkdownテーブルを使います。
セクション名も、Fields、Inputs、Outputs のように似ています。
AIはこれらを見比べて、かなり自然に「同じようなもの」と扱います。
その結果、あるモデル種別にしか存在しない列を、別のモデル種別にも追加してしまうことがあります。
例として、以下のようなズレが起きます。
# OK
| id | data | source | required | notes |
# NG
| id | data | source | required | ref | notes |あるいは、
# OK
| id | data | target | notes |
# NG
| id | data | target | ref | notes |こうしたズレは、単なる表記ゆれではありません。
パーサーが列位置を前提にしている場合、1列増えただけで、後続の値がすべてずれて読まれる可能性があります。
これは、AI生成Markdownを「文章」ではなく「構造データ」として扱うときに避けて通れない問題です。
“便利そうな列”が一番危ない
今回特に多かったのは、次のような列の追加です。
refruledescriptionnotessourcetarget
これらは、どれも設計情報としては自然な名前です。
AIにとっても使いやすい。
人間にとっても意味が分かりやすい。
だからこそ危険です。
たとえば、notes は多くのテーブルにありそうな列です。
しかし、すべてのFORMATに存在するとは限りません。
description も同じです。
自然言語の説明を入れたくなると、AIはすぐに追加しがちです。
でも、Model WeaveのようにMarkdownをモデルとしてパースする場合、列は自由に増やせません。
列を増やしたい場合は、FORMATを変更する必要があります。
AIがその場の判断で足してよいものではありません。
Markdownテーブルは見た目より壊れやすい
もう一つ問題になったのは、テーブルセル内の記述です。
Markdownテーブルでは、| が列区切りです。
そのため、TypeScriptやプログラミング言語では自然な次のような表記が、Markdownテーブルでは危険になります。
string | null人間には「文字列またはnull」と読めます。
しかしMarkdownテーブル内では、| が列区切りとして解釈される可能性があります。
同じように、Wikilinkのエイリアスも危険です。
[[DATA-USER|User]]Obsidianでは自然な書き方です。
しかし、Markdownテーブルの中では | を含むため、列崩れの原因になります。
つまり、Obsidianでは便利な記法でも、構造化テーブルの中では安全とは限りません。
型表記もシンプルに寄せる必要があった
AIは、ソースコードを読ませると、プログラム寄りの型表記を自然に使います。
たとえば、
string[]
Array<string>
Optional<string>
string | nullといった表記です。
コードの説明としては自然です。
しかし、MarkdownテーブルやViewer表示、将来のパーサー互換性を考えると、こうした表記はリスクになります。
特に Array<string> のような山括弧つき表記は、MarkdownやHTMLレンダリングと相性が悪い場合があります。string[] も、シンプルに見えても、フォーマット上は警告対象にした方が安全です。
そこで、Dogfoodモデルでは、型表記をできるだけ単純に寄せる方針にしました。
たとえば、ERの data_type では、
string
number
boolean
datetimeのような単純型を優先します。
複数値であることや任意項目であることは、型に詰め込まず、
requirednot_nullnotes
のような列で表現します。
これは少し地味ですが、かなり重要です。
プログラムとして自然な型表記が、Markdownモデルとして安全とは限らない。
この切り分けが必要でした。
frontmatterのWikilinkも注意が必要
もう一つ、Dogfoodで見えた落とし穴がfrontmatterです。
ObsidianではWikilinkをよく使います。
本文中であれば、次のような書き方は普通です。
[[DATA-MW-DFD-FLOW-ENTRY]]しかし、frontmatterはMarkdown本文ではなくYAMLです。
そのため、frontmatter内でWikilinkを書く場合は、クォートした方が安全です。
source: "[[DATA-MW-DFD-FLOW-ENTRY]]"未クォートのまま書くと、YAMLとして不安定になったり、ツールによって解釈が変わったりする可能性があります。
ここも、人間が見るだけなら気づきにくい部分です。
しかしAIに大量生成・更新させる場合、こうした小さな不安定要素が積み重なって、あとから大きな不整合になります。
対策としてガイドを作った
こうした問題が見えてきたので、DogfoodモデルではAI生成用の運用ガイドを作ることにしました。
主なルールは、次のようなものです。
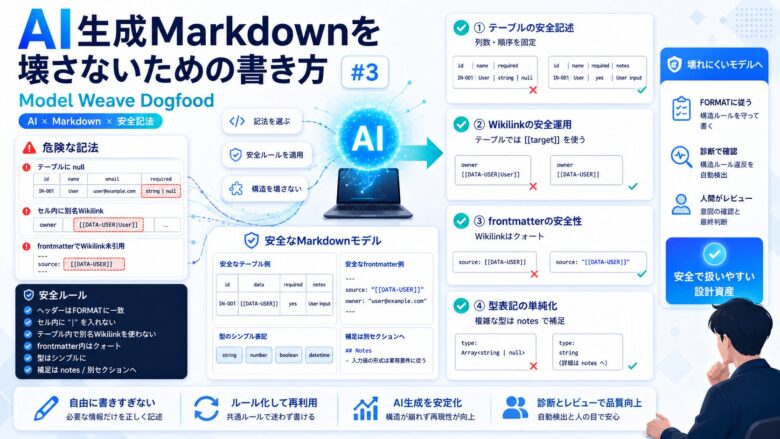
- MarkdownテーブルのヘッダーはFORMATに完全に合わせる
- AIの判断で列を追加しない
- 定義外の情報は
notesや任意セクションに逃がす - frontmatter内のWikilinkはダブルクォートで囲む
- テーブル内では
|を含む表記を避ける - Wikilinkエイリアスをテーブル内で使わない
- 型表記は単純型を優先する
- 配列性や任意性は型ではなく別の列やnotesで表現する
これは、Model Weave固有の運用ルールでもあります。
しかし、AIでMarkdownベースの設計資料を生成する場合には、かなり一般的な知見でもあると思います。
AIは「意味が通る文章」を作るのは得意です。
一方で、「厳密な列構造を壊さずに更新する」には、明確なルールと検証が必要です。
AIに任せるほど、形式が重要になる
今回のDogfoodで分かったのは、AIを使うほど形式が重要になる、ということです。
人間が手で1ファイルずつ書くなら、多少の表記ゆれはその場で気づけます。
しかしAIに複数ファイルを生成・更新させる場合、同じミスが広範囲に広がります。
しかも、AIの出力は一見すると自然です。
だからこそ危ない。
見た目には整ったMarkdownでも、FORMATから見ると壊れている。
文章としては正しいが、モデルとしては不正。
この状態が起きます。
AI生成の設計モデルを実用に近づけるには、プロンプトだけでは足りません。
- FORMAT仕様
- 生成ルール
- 診断
- レビュー
- 修正ガイド
このあたりをセットで用意する必要があります。
おわりに
AIにMarkdownモデルを作らせることは、十分に実用的です。
既存ソースやドキュメントから、設計モデルの初稿を作る。
人間がゼロから書くより速く、構造の叩き台としても使いやすい。
ただし、AIが生成したMarkdownをそのまま信じることはできません。
特に、Markdownテーブルを構造データとして扱う場合、列の追加、ヘッダーの不一致、セル内の |、Wikilinkエイリアス、複雑な型表記などが問題になります。
今回のDogfoodで分かったのは、AIに設計モデルを作らせるには、自由に書かせることよりも、壊してはいけない構造を明確にすることが重要だということです。
Markdownは自由に書ける形式です。
しかし、それを設計資産として機械的に扱うなら、自由さを少し制限する必要があります。
次回は、今回触れた内容の中でも、Markdownテーブル、Wikilink、型表記を安全に扱うための具体的な記法について、もう少し詳しく整理します。
Model Weave Dogfoodサンプルはこちらから
今回紹介している初回公開版ソースベースDogfood を公開しています。
ご興味のある方は是非ご覧ください。
コメント