はじめに
最近、Model Weave自身の構造を、Model Weaveのモデルとして整理する取り組みを進めました。
いわゆる Dogfood です。
自分で作っているツールを、自分自身の開発や分析に使ってみる、というものです。
Model Weave は、Markdownを正本として、設計モデルや図、プレビュー、診断結果などを扱うための Obsidian プラグインです。Markdownファイルを元に、図やプレビュー、診断、PNG出力などを派生させるという考え方で作っています。
今回のDogfoodでは、Model Weaveのソースコードやドキュメントを題材にして、AIを使いながら設計モデルを作っていきました。
やりたかったことは、単に「Model Weaveのサンプルを作る」ことではありません。
既存のソースコードや仕様資料から、AIを使って設計の地図を作り、それを人間がレビューできる形にできるか。
その実験として、Model Weave自身をModel Weaveで読んでみました。
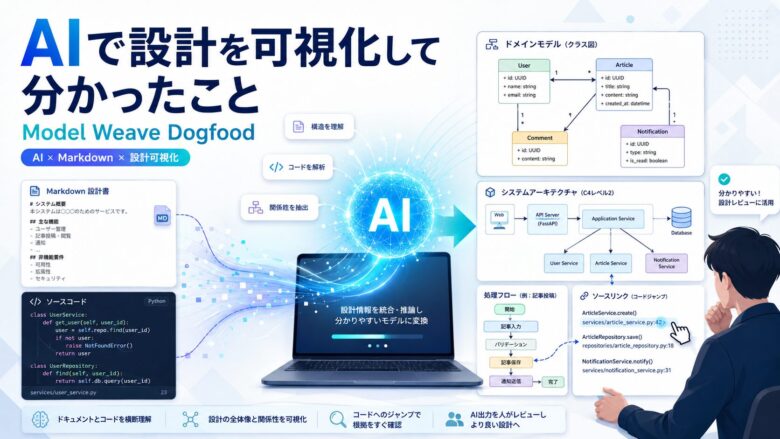
AIで設計を可視化する、という試み
開発が進んでくると、ソースコード、README、仕様メモ、サンプル、フォーマット定義などが増えていきます。
個別のファイルを見れば分かることは多いのですが、全体として見ると、次のようなことが気になってきます。
- この機能はどのソースファイルで実装されているのか
- このMarkdownフォーマットはどのパーサーに対応しているのか
- レンダラー、Viewer、設定、診断処理はどう関係しているのか
- ドキュメントに書かれていることは、実装と合っているのか
- AIに修正を依頼するとき、どの情報を渡せばよいのか
こうした情報は、頭の中だけで管理しているとすぐに曖昧になります。
そこで、Model Weaveの機能、フォーマット、実装ファイル、ドキュメントの関係を、Markdownモデルとして整理していきました。
AIにソースやドキュメントを読ませ、モデルの下書きを作らせる。
そのモデルをModel Weaveで表示し、人間が確認する。
必要に応じて、元のソースコードに戻って確かめる。
この流れを試しました。
期待していたこと
最初に期待していたのは、比較的シンプルなことでした。
AIに既存ソースを読ませれば、ある程度の設計モデルは作れるはずです。
たとえば、
- 主要なクラスやモジュールを抽出する
- パーサーやレンダラーの役割を整理する
- Markdownフォーマットごとの構造をまとめる
- ソースファイルと機能の対応を記録する
- 関連するドキュメントやサンプルへのリンクを付ける
といったことです。
人間がゼロから設計書を書くより、AIに初稿を作らせた方が速い。
これは実際にかなり有効でした。
ただし、やってみるとすぐに分かりました。
AIに任せれば設計資料が完成する、というほど単純ではありません。
実際に起きたこと
AIは、かなり自然にモデルの下書きを作ってくれます。
しかし、Model WeaveのようにMarkdownを機械的に解釈するツールでは、Markdownとして「それっぽく見える」だけでは不十分です。
たとえば、Markdownテーブルの列構成です。
AIは、文脈上あった方が便利そうな列を勝手に追加することがあります。
app_process の Inputs に、本来は存在しない ref 列を追加する。Outputs にも同じように ref 列を足す。
他のモデルで使っていた notes や description を、別のモデルにも自然に混ぜてしまう。
人間が読むだけなら、多少列が増えても意味は分かります。
しかし、パーサーはFORMATで決められたヘッダー構造を前提にしています。
列の名前、順序、数がずれると、モデルとしては壊れます。
これは大きな気づきでした。
AIに設計モデルを生成させる場合、単に「この形式で書いて」と指示するだけでは足りません。
壊してはいけない構造を、明確にルール化する必要があります。
Markdownは自由だが、モデルとして使うなら制約が必要
Markdownの良さは、自由に書けることです。
人間が読みやすく、Gitで管理しやすく、Obsidianでも扱いやすい。
AIにも読ませやすい。
これはModel Weaveの重要な前提です。
一方で、Markdownを「設計モデルの正本」として使うなら、自由すぎる記述は危険になります。
特に壊れやすかったのは、次のような部分でした。
- Markdownテーブルのヘッダー
- テーブル内の
|記号 [[target|label]]のようなWikilinkエイリアスstring | nullのようなUnion型表記Array<string>やOptional<string>のような型表記- frontmatter内の未クォートWikilink
- 実装済み機能と将来構想の混在
プログラムの型表記としては自然でも、Markdownテーブル内では安全とは限りません。
string | null は、人間には「文字列またはnull」と読めます。
しかし、Markdownテーブルでは | が列区切りとして扱われるため、列崩れの原因になります。
Array<string> も、HTMLタグのように解釈されたり、表示や解析で問題になる可能性があります。
つまり、AIに設計モデルを書かせるには、AIが賢いかどうかだけでなく、安全に書ける表記ルールが必要になります。
ガイドを作る必要が出てきた
このため、Dogfoodを進める中で、いくつかの運用ガイドを作ることになりました。
たとえば、
- AI生成運用ガイド
- frontmatter内Wikilink安全記述ガイド
- Markdownテーブルセル安全記述ガイド
といったものです。
これらは、単なるメモではありません。
AIにModel WeaveのMarkdownモデルを生成・更新させるとき、構造を壊さないためのルールです。
特に重要なのは、次のような点です。
- FORMATで定義されたテーブルヘッダーを守る
- 勝手に列を追加しない
- 追加情報は
notesや任意セクションに逃がす - frontmatter内のWikilinkはダブルクォートで囲む
- Markdownテーブル内では
|を避ける - 型表記は単純型を優先する
- 実装済みと将来構想を区別する
これらは、Model Weave固有の話でもありますが、同時に、AIで設計資料を生成するうえでかなり一般的な知見でもあると思います。
AIには「情報源の整備」も必要だった
もう一つ大きかったのは、AIに渡す情報源の問題です。
今回の作業では、GeminiやChatGPTも使いました。
しかし、途中でいくつか問題が出ました。
たとえば、Gemini側では .gitignore の対象になっているソースをうまく読めない場面がありました。
また、ChatGPT側では、Dogfoodモデル内に含まれる将来構想を、実装済み機能のように扱ってしまい、未実装機能を前提にした指示を出し始めることがありました。
これは、AIが悪いというより、渡している情報源の状態に問題があります。
AIは、手元にある情報から推論します。
そこに古い情報、未実装の構想、最新ソースから外れたモデルが混ざっていると、当然ながら出力もずれます。
そこで、情報源として次のものを揃える必要が出てきました。
- 最新のソースコード
- 最新のDogfoodモデル
- FORMAT仕様
- README
- AI生成運用ガイド
- 実装済みと将来構想の区分
AIに設計を任せる前に、AIが参照する情報源を整える。
これも今回の大きな学びでした。
設計モデルはコードに戻れてこそ強い
Dogfoodを進める中で、もう一つ強く感じたことがあります。
設計モデルは、図としてきれいに表示できるだけでは不十分です。
特にAIが生成したモデルの場合、その内容が本当に正しいかどうかを確認する必要があります。
そのためには、モデル上の要素から、元のソースコードへ戻れる導線が必要です。
「この機能はこのファイルで実装されている」
「このモデル要素はこのソースに対応している」
「この説明はこの実装を元にしている」
こうした関係を辿れないと、人間がレビューしづらくなります。
この気づきから、Model Weave 0.1.3では、Source Linksからコードへジャンプする機能を入れました。
これは、Dogfoodを実際にやってみたからこそ必要性がはっきりした機能です。
モデルにソースパスを書くだけでは足りない。
レビュー中に、その場でコードを開きたい。
この導線があることで、設計モデルは単なる説明資料ではなく、実装へ戻るための地図になります。
今回分かったこと
今回のDogfoodで分かったのは、AIで設計を可視化すること自体はかなり現実的だということです。
既存のソースやドキュメントをAIに読ませ、設計モデルの下書きを作らせる。
それを人間が確認し、修正する。
MarkdownとしてGit管理する。
必要に応じて図やプレビューで確認する。
この流れは十分に使えます。
ただし、重要なのは、AIに自由に書かせることではありません。
AIが壊してはいけない構造を定義すること。
AIに渡す情報源を整えること。
実装済みと将来構想を区別すること。
そして、人間が元コードに戻って検証できる導線を用意すること。
このあたりが揃って、初めてAI生成の設計モデルは実用に近づきます。
おわりに
Model WeaveのDogfoodは、単なるサンプル作成ではありませんでした。
AIで設計を可視化しようとしたときに、どこが壊れやすいのか。
どんな運用ルールが必要になるのか。
どのように元ソースへ戻れるようにすべきか。
そうしたことを確認する実験になりました。
Dogfoodを通じて分かったのは、AIに設計モデルを作らせるには、AIの自由度を上げるだけでなく、壊してはいけない構造を明確にすることが重要だということです。
Markdownは、人間にもAIにも扱いやすい形式です。
しかし、それを設計資産として使うなら、形式、ルール、情報源、検証導線が必要になります。
このシリーズでは、今回のDogfoodで見えてきたことを、いくつかに分けて整理していきます。
次回は、AIにMarkdownモデルを生成させたときに起きた、テーブル構造の崩れやFORMAT不一致の問題について書いていきます。
Model Weave Dogfoodサンプルはこちらから
今回紹介している初回公開版ソースベースDogfood を公開しています。
ご興味のある方は是非ご覧ください。

コメント