ここまで、Model Weaveを作り始めた理由から、Obsidianプラグインへ切り替えた経緯、ER図・クラス図・DFDをどう扱うかまでを書いてきた。
今回は少し視点を変えて、リリース前の段階でModel Weaveが今どこまでできるようになっているのかを整理してみたい。
まだ完成形というわけではない。
ただ、Markdownを正本にして、そこから図やPreviewを生成し、Obsidian上で設計を読みやすくするという基本線はかなり見えてきた。
ここで一度、今できること、安定してきた領域、まだ発展中の領域をまとめておく。
ここまでで、ツールとしての輪郭が見えてきた
Model Weaveは、最初から巨大な統合モデリングツールを目指しているわけではない。
目指しているのは、もっと素朴なところにある。
設計情報をMarkdownで書き、それをObsidian上で読みやすく表示する。
必要に応じて図として確認し、関係を辿り、診断を見て、レビューしやすくする。
つまり、図を作ること自体が目的ではない。
図はあくまで、Markdownで書かれた設計情報を理解するための派生ビューだ。
この考え方は、Model Weaveのかなり中心にある。
Excelのように自由度が高すぎる形式では、後からデータとして扱いにくい。
一方で、専用モデリングツールに閉じた形式では、ツールがないと読みにくくなる。
その中間として、Markdownで構造を持たせ、必要な見え方をプラグイン側で作る。
この方向性で作ってきた結果、今は少なくとも、ER図、クラス図、DFD、data_objectあたりまでは、ツールとしての使い道が見えるところまで来た。
Markdownを正本にして、図やPreviewを生成する
Model Weaveで一番大事なのは、Markdownを正本にすることだ。
ER図を描くためにだけ存在するファイルではなく、ERのEntity定義そのものをMarkdownで持つ。
クラス図を描くためにだけ存在するファイルではなく、Classの属性やメソッドや関係をMarkdownで持つ。
DFDでも、Mermaidを直接書くのではなく、ObjectsとFlowsをMarkdownの表として書く。
そこから、図やPreviewを生成する。
この順番が大事だと思っている。
図を正本にすると、見た目を整えることに意識が寄りやすい。
もちろん図の見やすさは大事だが、設計資産として残したいのは、線の位置や箱の座標ではなく、そこに書かれている意味の方だ。
だからModel Weaveでは、Markdownを編集し、その結果として図が出る、という形にしている。
Mermaid、SVG、Preview UI、PNG Exportは、いずれもMarkdownから作られる派生出力という位置づけになる。
rendererを切り替えても、Markdownの形式そのものは変わらない。
これにより、設計の正本と見え方を分けられる。
そして、正本であるMarkdownは、Obsidianの検索、リンク、差分管理、ファイル管理の中に自然に残せる。
ER図・クラス図・DFDを扱えるようになった
現時点で、Model Weaveの中心になっているのは、ER図、クラス図、DFDだ。
まずERでは、er_entity と er_diagram を扱う。
er_entity は、テーブルに相当する単体定義ファイルだ。
論理名、物理名、Columns、Indexes、Relationsを持つ。
Relationは、自テーブルから出る関係だけを正本として持たせている。
逆向きの関係は、プラグイン側で逆引きすればよい。
一方で、er_diagram は複数のEntityを束ねて表示するための図表定義ファイルになる。
diagram自体にRelationの正本は持たせず、対象EntityからRelationを集約して図として表示する。
この分け方にしたことで、ERの正本はテーブル定義側に残る。
diagramは、どのEntity群を見たいかを指定するビューとして扱える。
クラス図では、class と class_diagram を扱う。
class は、クラス、インターフェース、抽象クラスなどの単体定義ファイルだ。
Attributes、Methods、RelationsをMarkdownテーブルで管理する。class 側のRelationsは、そのファイル自身を起点とする関係だけを持つ。
一方で、class_diagram は複数のclassを束ね、図全体として見せたいRelationを持てる。
ERと完全に同じ形にはしていない。
ERではRelationをEntity側に強く寄せたが、Classでは単体定義とdiagram定義の両方に役割を持たせている。
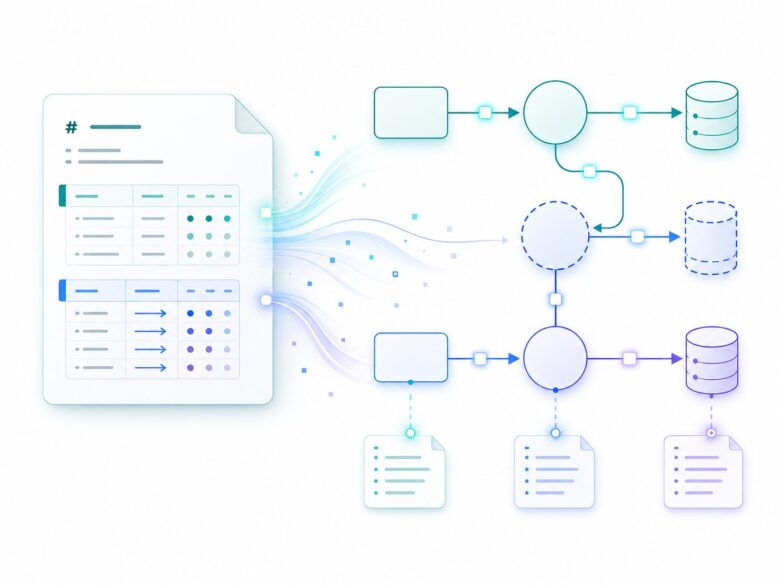
DFDでは、さらに考え方が変わる。
DFDの主役は、外部実体やプロセスそのものというより、データの流れだ。
そのため、dfd_diagram にObjectsとFlowsを持たせる。
Flowの正本はdiagram側に置く。
このとき、すべてのObjectを個別ファイル化しなくてもよいようにした。
diagram内だけで使うlocal objectを許容している。
軽く描き始めて、必要になったものだけ dfd_object として切り出せる。
また、DFDはMermaid-firstに寄せている。
DFDでは線の自動レイアウトの価値が大きいので、custom rendererを維持するより、MarkdownのObjects / FlowsからMermaidの flowchart LR を生成する方が合っていると判断した。
ここまでで、Model Weaveは「構造を見るER / Class」と「流れを見るDFD」の両方を扱えるようになってきた。
data_objectで、流れるデータや入出力も扱える
DFDが扱えるようになると、次に気になるのは「そのFlowで流れているデータは何か」だ。
たとえばDFDで、
- 入庫予定データ
- 入庫予定CSV
- 作業指示
- 作業実績
- 在庫更新
のようなFlowを書けるようになる。
ただ、そのデータの中身まではDFDだけでは表現しきれない。
そこで data_object が出てくる。
data_object は、Model Weaveにおけるデータ構造、電文、ファイルレイアウト、画面フォーム値、API payloadなどを表すフォーマットだ。
DFD上を流れるデータ、画面入力値、app_processのInput / Output、API request / response、CSV、固定長ファイルなどを扱う中間データ定義として位置づけている。
ここが入ると、Model Weaveは単なる図ビューアではなくなってくる。
DFDでデータの流れを見る。
data_objectで流れるデータの中身を見る。
ERで保存先のテーブルを見る。
mappingで項目対応を見る。
screenやapp_processで、画面や処理とのつながりを見る。
もちろん、今すべてが完成しているわけではない。
ただ、少なくとも「設計情報を横につなげていく」方向性は見えてきた。
特に業務システムでは、CSV、固定長ファイル、API payload、画面入力、DB保存、バッチ処理などが入り混じる。
このとき、データの形を data_object として切り出せると、AIにも人間にも説明しやすくなる。
DFDで「どこからどこへ流れるか」を見て、data_objectで「何が流れるか」を見る。
これは、Model Weaveのかなり大事な使い道になると思っている。
Viewerでは、診断やPNG出力もできる
Model Weaveは、Markdownを書くだけではなく、Obsidian上で見るためのViewerを持っている。
Viewerでは、図やPreviewを表示する。
ERやClassでは、custom rendererとMermaid rendererを切り替えられるようにしている。
custom rendererは、詳細確認やクリック遷移、診断表示のようなレビュー用途に向いている。
Mermaid rendererは、全体像や関係、流れを自動レイアウトで見たいときに向いている。
DFDについては、実質的にMermaid-firstにしている。
そのため、DFDではrendererを切り替えるより、Objects / Flowsから安定してMermaidを生成することを優先している。
Viewerでは、zoom、fit、100%、pan、diagnostics、上下リサイズ、PNG exportといった機能も持たせている。
これは、図をただ表示するだけではなく、レビューや資料化に使えるようにするためだ。
特にPNG exportは、設計レビューやブログ、説明資料に図を貼るときに便利だ。
toolbarやdiagnostics panelではなく、図本体を出力する方針にしている。
また、diagnosticsも重要だ。
Markdownを正本にする以上、参照切れや未解決のID、重複、形式の揺れは避けられない。
そこを人間が目で全部チェックするのはつらい。
だからViewer上でWarningsやErrorsを出し、どこがおかしいのかを見えるようにする。
このあたりは、Model Weaveを「図を出すツール」ではなく、「設計を読みながら直すツール」に近づけるための部分だと思っている。
まだ発展中のフォーマットもある
現時点で、安定寄りに見えてきたフォーマットと、まだ発展中のフォーマットがある。
安定寄りなのは、まずこのあたりだ。
class
class_diagram
er_entity
er_diagram
dfd_object
dfd_diagram
data_objectER、Class、DFD、data_objectは、Model Weaveの基本的な方向性を示すものとしてかなり固まってきた。
もちろん、今後も改善は続く。
ただ、少なくとも「何を表すフォーマットなのか」は整理されてきている。
一方で、発展中のフォーマットもある。
screen
app_process
rule
codeset
message
mappingこれらは、かなり重要だ。
むしろ、業務システム設計としてはここから先が本番とも言える。
screenでは、画面構成、項目、操作、処理呼び出し、画面遷移を扱う。
app_processでは、UIを持たないアプリケーション処理単位を扱う。
ruleでは、入力チェックや業務条件を扱う。
codesetでは、ステータスや選択肢のようなコード体系を扱う。
messageでは、表示文言やエラー文言を扱う。
mappingでは、screen、data_object、ER、app_processなどの項目対応を扱う。
ただ、この領域は最初から厳密化しすぎると、かえって使いにくくなる。
たとえば処理手順やエラー処理は、初期設計では自然言語で冗長に書いた方がよいことが多い。
画面仕様も、最初からCSSやピクセル単位のレイアウトを表現するより、画面の意味、項目、操作、遷移を整理できる方が大事だ。
そのため、これらのフォーマットは「人間とAIが読める設計情報」として育てていく方針にしている。
最初は自然言語を許容し、必要に応じてruleやmappingへ切り出す。
AIレビューで重複や不整合を見つけ、少しずつ整えていく。
ここは、Model Weaveの今後かなり面白くなる部分だと思っている。
次は、実際にどう使うかを見ていく
ここまでで、Model Weaveの現在地を整理してきた。
Markdownを正本にする。
図やPreviewは派生ビューとして扱う。
ERやClassでは構造を見る。
DFDでは流れを見る。
data_objectでは、流れるデータや入出力の中身を見る。
Viewerでは、図を確認し、diagnosticsを見て、必要に応じてPNG出力する。
このあたりが、現在のModel Weaveでまず試しやすい使い方になる。
もちろん、すべてが完成しているわけではない。
フォーマットには安定してきたものもあれば、これから育てていくものもある。
ただ、Markdownを中心に設計情報を残し、Obsidian上で確認しながら育てていくという考え方は、かなり形になってきた。
次からは、実際の使い方に進んでいきたい。
たとえば、次のような内容だ。
- インストール方法
- サンプルの見方
- ER図を作る流れ
- クラス図を作る流れ
- DFDを軽く描く流れ
- MarkdownからPNGを出力する流れ
開発経緯や設計判断の話から、実際に手を動かして使う話へ移っていく。
まずは小さなサンプルから、Model Weaveでどんな設計の読み方ができるのかを見ていきたい。

コメント